Как конвертировать PDF в OCR
Когда печатный документ сканируется и сохраняется в формате PDF, компьютер не видит разницы между отсканированной страницей текста и фотографией. Таким образом, вы не можете искать или выбирать какой-либо текст на странице для копирования и вставки. Если вы хотите найти или выделить текст, вы должны запустить оптическое распознавание символов (OCR) в документе. Adobe Acrobat Professional предоставляет эту функцию, а бесплатная версия Adobe Acrobat — нет. Если у вас нет Acrobat Professional, обратите внимание, что для выполнения оптического распознавания символов в PDF-документе существует программное обеспечение, отличное от Acrobat Professional, и его можно найти с помощью поиска в Интернете.
Шаг 1
Загрузите Adobe Acrobat Professional. Функция OCR в Acrobat Professional недоступна через подключаемый модуль веб-браузера, поэтому необходимо загрузить саму программу.
Шаг 2
Загрузите документ PDF с текстом, который нельзя выделить для копирования и вставки. Такие документы обычно создаются путем сканирования документа и сохранения документа в формате Adobe Acrobat PDF. (См. Ресурсы для образца документа, если вы хотите попрактиковаться с ним.)
Шаг 3
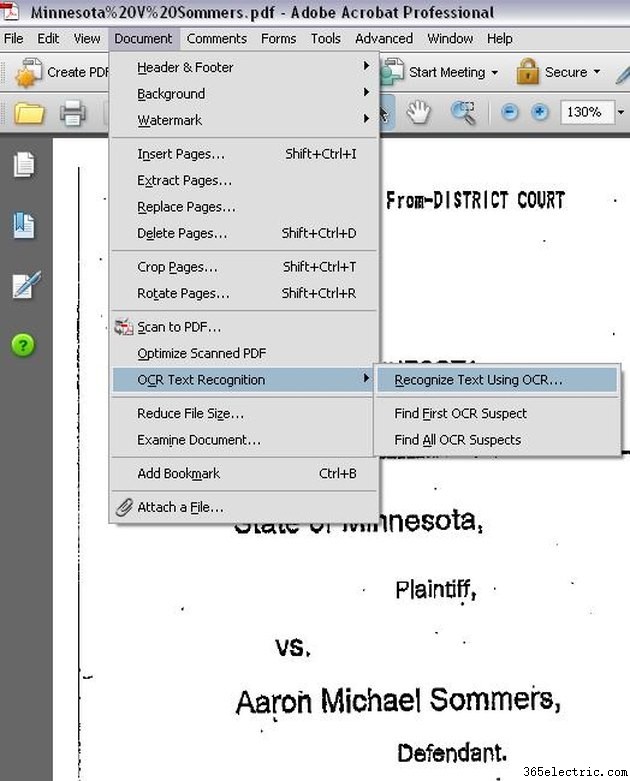
Запустите OCR в документе. В Adobe Acrobat Professional щелкните меню «Документ», затем выберите «Распознавание текста OCR», а затем нажмите «Распознать текст с помощью OCR».
Шаг 4
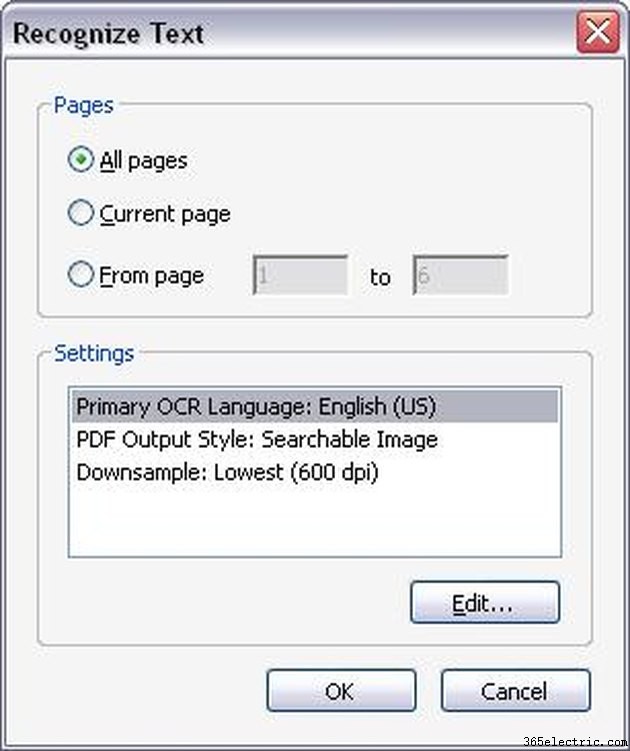
Выберите применимые параметры OCR. После того, как вы нажмете «Распознать текст с помощью OCR», появится новое окно с предложением выбрать диапазон страниц, на котором вы хотите запустить OCR. Вы можете запустить OCR для всего файла PDF или ограничить распознавание только несколькими страницами. После того, как вы выберете количество страниц, на которых вы хотите запустить OCR, нажмите «ОК». Теперь Acrobat Professional начнет распознавать текст на страницах вашего документа.
Шаг 5
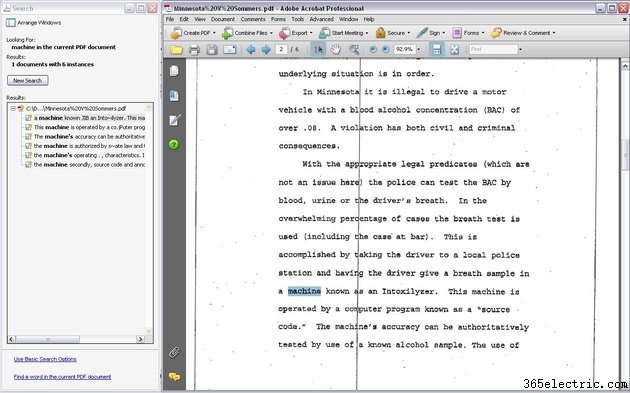
Ищите текст после завершения OCR и копируйте и вставляйте текст так же, как вы могли бы это делать с PDF-файлом, полученным из Microsoft Word. Обратите внимание, однако, что технология OCR не идеальна. OCR может неправильно распознавать определенные слова и полностью пропускать текст. OCR лучше всего работает с идеально четкими изображениями текста, что не всегда возможно с отсканированными документами.